
Big Data está cambiando el mundo donde vivimos y, tarde o temprano, los CTO´s de las organizaciones han de ir familiarizándose con el abanico de soluciones y proveedores que hay en el entorno de Big Data. Sí bien es cierto que aún es un mercado en proceso de madurez ya no son soluciones adoptadas únicamente por early-adopters. Todos los grandes están apostando por Hadoop y es que cuando hablamos de Big Data quizás la tecnología que ha propiciado a su mayor difusión ha sido Hadoop. Con la creación de Hadoop en 2005 se ha cubierto la necesidad de analizar grandes volúmenes de datos no estructurados con una solución más barata que las existentes, con mayor rendimiento y alto grado de personalización. El stack de Hadoop es capaz de funcionar con gran variedad de arquitecturas hardware comodity y es una solución de análisis ágil y económica para las empresas con grandes necesidades en el análisis de los datos, sin importar el tamaño de la organización. Hadoop es una gran revolución en el procesamiento y análisis de cantidades masivas de datos. Según Gartner en 2012 su Hype cycle for Emerging Technologies Big Data se encuentra llegando al pico de las expectativas infladas.

Hadoop es 100% open source y está en continuo desarrollo. El
crodwsourcing (comunidad de desarrolladores que contribuyen en crear SW)
proporciona un alto grado de innovación y continúa mejora, de hecho, son los
propios empleados de empresas punteras en soluciones Haadop, los que
contribuyen a la mejora de la plataforma. Normalmente por propios intereses de
las compañías, que tienen mayores
necesidades, son los que incrementan las funcionalidades y las capacidades de
Haadop.
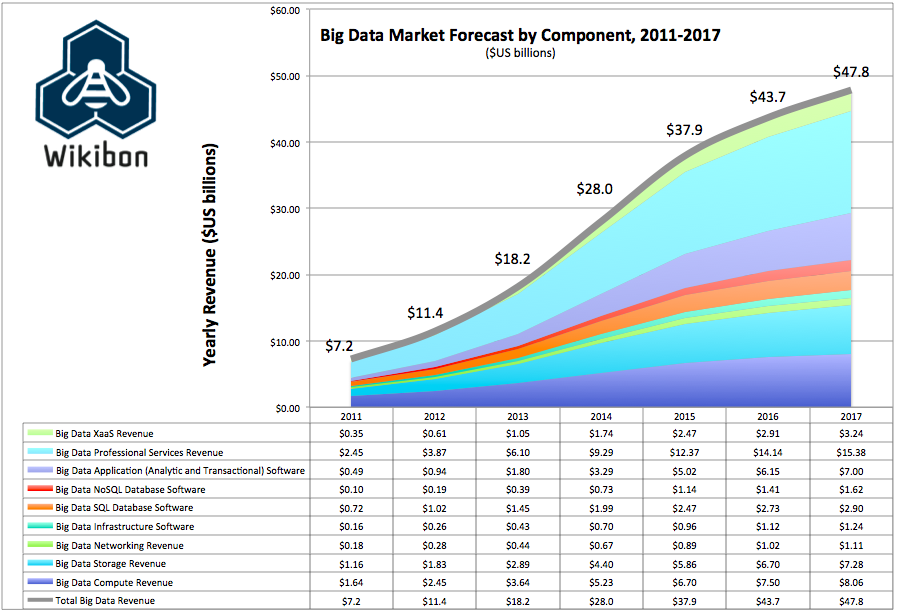
Dadas las circunstancias de inmadurez de
muchas de las opciones voy a basarme en el siguiente criterio para escoger
los proveedores para el artículo:
·
La oferta actual de soluciones Big
Data.
·
La estrategia de la empresa en
este ámbito.
·
Presencia en el mercado.
·
Integración con otros proveedores.

Considerado el proveedor de servicios más importante de Hadoop en la nube (Amazon fue de las empresas pioneras en utilizar las funcionalidades de Hadoop y gran colaborador en sus avances). El servicio Elastic MapReduce (EMR) ya ha logrado una considerable adopción en grandes y medianas empresas. Para una amplia gama de usuarios, AWS EMR es la vía de acceso principal a una plataforma Hadoop de nivel empresarial ya que no requiere ningún tipo de inversión ni en hardware ni en software dado que es una solución en nube. Permite un pago por uso que se contabiliza por horas y por espacio en disco consumido. Ofrece así unas posibilidades de escalabilidad muy potentes.
Desde principios de este año ofrece la posibilidad de utilizar un
servicio para DataWare con Redshift (solución que pretende competir con los
Appliance EDW de IBM, EMC, Oracle o HP).
AWS cuenta con una amplia gama de partners asociados que ofrecen
servicios de acceso/consulta, modelado y desarrollo, integración de datos,
administración de clúster y aplicaciones empresariales de datos Hadoop. AWS es un proveedor rentable, sobre todo
para medianas empresas y start-ups. Se ofrece acceso bajo demanda a las
tecnologías Big Data tanto para recopilar, almacenar, calcular y colaborar en
torno a conjuntos de datos de todos los tamaños, desde el servicio de Hadoop
administrado, Elastic MapReduce, a la poderosa familia de procesadores Intel
Xeon E5. Aparte de los beneficios en costes, también es necesario indicar que
la rápida adopción de esta tecnología permite una puesta en marcha en cuestión
de días, en lugar de en meses. Permite la integración con un número reducido de
aplicaciones de BI.
IBM

IBM cuenta con la plataforma y portfolio de aplicaciones más profunda
de Big Data, según Forrester, es el líder absoluto del mercado, el más fuerte
en aspectos de estrategia y el que mejor gama de productos ofrece.
Está bien establecido en
su mercado. Tiene su propia distribución de Hadoop con una gran cantidad de
servicios profesionales, amplios programas de I+D+i en el desarrollo de las
tecnologías asociadas. En resumen, IBM tiene un número considerable de
soluciones y servicios para Big Data (engloba tanto hardware como software),
aparte de una gran cartera de clientes y software, aplicaciones aparte de
alguna que otra oferta de servicios en la nube para BigData.
Posee una oferta de hardware muy potente. Con la última compra de la
start-up Texas Memory Systems ha potenciado su oferta de almacenamiento de alto
rendimiento con la familia IBM FlashSystems.
Al igual ocurre con la familia de IBM Pure Sytems&Data que se han hecho uno
de los referentes en el mercado de Appliance OLAP y nubes privadas.
Aparte posee el paquete de productos InfoSphere
(Infosphere Streams, InfoSphere BigInsights, InfoSphere Data Explorer, InfoSphere Information Server y InfoSphere Master Data Management) a nivel Software, uno de
los más fuertes del mercado. Cubre 360º la arquitectura para explotar Big Data.
Permite integrar con proveedores importantes de analítica como SAS, Cloudera,
MicroStrategy, Oracle, etc. Las facilidades de integración con otros productos
son posibles pero no de fácil implantación. Su appliance Netezza ofrece mejor
rendimiento para base de datos OLTP que la competencia, es fácil de instalar y
usar, sus procesadores FPGA (Field Programmable array) mejoran el rendimiento
ante cuellos de botella.
Ofrecen servicios profesionales muy completos (formación, consultoria,
integración, mantenimiento, etc).

Greenplum fue adquirida por EMC a mediados del 2010, formando la división de Big Data llamada EMC Greenplum, es la primera empresa en utilizar Appliances de MPP con Hadoop (todas las funciones de Hadoop + las mejoras de rendimiento de MPP para OLAP). También tiene su propio SW de distribución de Hadoop, su portfolio de soluciones es muy sólido en productos de almacenamiento, y tiene una amplia fuerza de servicios profesionales de consultores técnicos de EMC y los datos científicos con experiencia Hadoop.
EMC Greenplum tiene soluciones Software que cubren prácticamente todas
las soluciones empresariales y herramientas de integración de datos propios (Greenplum
Unified Analytics Platform (UAP), Greenplum Database MPP, Pivotal HD, Greenplum
Chorus, GreenPlum Analytic Lab, Greenplum MR (MapReduce)). Posee fuertes
alianzas con proveedores de software especialistas en soluciones para la
analítica.
Su producto más extendido es Greenplum Database MPP y Pivotal HD.
Ofrece servicios profesionales (Cientificos de datos, desarrolladores, etc).

Oracle recientemente a través de su alianza con Cloudera ofrecen Oracle BigData Appliance que ofrece los beneficios de Hadoop y sus herramientas más las funcionalidades de tecnología MPP que posee Exadata. A parte permite la integración con otras distribuciones de Hadoop gracias a Oracle Loader for Hadoop (OLH), Oracle Direct Connector for Hadoop Distributed File System (HDFS), Oracle Data Integrator Application Adapter for Hadoop, Oracle R Connector for Hadoop, Oracle Big Data Connectors. Al catálogo de productos hay que añadir su solución para in-memory Exalytics y su software In-Database Analytics (Oracle R Enterprise, In-Database Data Mining , In-Database Text Mining , In-Database Semantic Analysis , In-Database Spatial y In-Database MapReduce ) que tiene gran aceptación. Incluyen una fuerte estrategia a nivel hardware que cubriría toda la arquitectura necesaria para Big Data y cuenta con su ventaja en cuanto al SW de BBDD. Ofrecen todo tipo de servicios profesionales apoyados por Cloudera en la parte de Hadoop.

HP compro Vertica en 2011. Con la compra de esta start-up HP completa
su oferta hardware y software para dar solución a sus clientes en Big Data. Su
solución basada en MPP ofrece posibilidades de explotar el appliance con
Hadoop. Posee alianza con Cloudera para integrar su solución de Hadoop. Tiene
alianzas con los principales proveedores de soluciones de analítica. Su
presencia en el mercado ha crecido con respecto a este tipos de soluciones
gracias a su posicionamiento en los servicios que ofrece y clientes que posee. Su
posibilidades de integración con Hadoop son con MapReduce, Sqoop y HDFS por lo
que limita su capacidad de integración con respecto a otros proveedores (no permite
Hbase, Hive o Pig). Posee el Appliance más barato del mercado salvo la oferta
en la nube que es más barata. Ofrece servicios profesionales completos.
Teradata/Aster.

Proveedor referente y pionero en ofrecer Appliance para base de datos OLAP con procesamiento MPP. Adquirió la start-up Aster Data en 2011. Completa su oferta con integración con Hadoop a través de distintos servicios (Aster SQL-H y Aster-Hadoop Adaptor) en la que permite explotar el appliance con SQL y utilizar el potencial de Apache Hadoop HCatalog (MapReduce, Hive, Pig y HDFS) . Servicios profesionales completos. Su Appliance es el mejor como Datawarehouse, soporta aumento de usuarios sin degradación y es más escalable que el resto de la competencia.
Proveedor referente y pionero en ofrecer Appliance para base de datos OLAP con procesamiento MPP. Adquirió la start-up Aster Data en 2011. Completa su oferta con integración con Hadoop a través de distintos servicios (Aster SQL-H y Aster-Hadoop Adaptor) en la que permite explotar el appliance con SQL y utilizar el potencial de Apache Hadoop HCatalog (MapReduce, Hive, Pig y HDFS) . Servicios profesionales completos. Su Appliance es el mejor como Datawarehouse, soporta aumento de usuarios sin degradación y es más escalable que el resto de la competencia.

Se trata de otro de los principales proveedores de distribución de Hadoop.
Proporciona facilidad de uso, fiabilidad y ventajas de rendimiento para
aplicaciones de base NoSQL y Hadoop. Tiene la gama de productos de familia
Hadoop más amplia del mercado. La fiabilidad de su solución se consolida con
una amplia gama de socios con soluciones BigData. MapR ofrece un rendimiento de
más de un millón de operaciones por segundo. Proporciona ventajas de
escalabilidad con soporte de hasta un billón de tablas a través de miles de
nodos. M7 también proporciona una recuperación instantánea de fallos,
asegurando la disponibilidad del 99,999% para aplicaciones HBase y Hadoop
utilizando infraestructura propia y las de Amazon, Google y HP en la nube. No
proporcionan servicios profesionales de forma directa aunque poseen alianzas
estratégicas con consultoras importantes del sector de las TIC. Integración con soluciones de analítica
de SAS, MicroStrategy, Datameer, etc.
Cloudera

Hadoop es el pure-play con la mayor adopción. El core de su negocio es su distribución de Apache Hadoop. Es el de mejor acogida por parte de empresas que adoptan este tipo tecnologías al comienzo de su expansión (mas conocidas como early-adopters) y además también es muy popular entre los proveedores de servicios basados en Hadoop en la nube. Con su nueva versión Impala mejora muy considerablemente su distribución de Hadoop.
Hadoop es el pure-play con la mayor adopción. El core de su negocio es su distribución de Apache Hadoop. Es el de mejor acogida por parte de empresas que adoptan este tipo tecnologías al comienzo de su expansión (mas conocidas como early-adopters) y además también es muy popular entre los proveedores de servicios basados en Hadoop en la nube. Con su nueva versión Impala mejora muy considerablemente su distribución de Hadoop.
Cloudera tiene un servicio profesional de gran calidad y creciente. Cloudera
no ofrece EDW propia, no proporciona herramientas de modelado de Hadoop y no ofrece la integración de datos
real-time/lowlatency. Sin embargo, Cloudera tiene fuertes asociaciones con
otros proveedores de tecnología en la mayoría de las áreas en las que su propia
cartera carece de una oferta.
Hortonworks
 Ofrece servicios profesionales y software para el ecosistema de Hadoop. Nació como
una empresa de la mano de Yahoo y Benchmark Capital en junio de 2011. Su
principal actividad es la de fomentar el uso de una distribución de Apache
Hadoop, Hortonworks Hadoop.
Ofrece servicios profesionales y software para el ecosistema de Hadoop. Nació como
una empresa de la mano de Yahoo y Benchmark Capital en junio de 2011. Su
principal actividad es la de fomentar el uso de una distribución de Apache
Hadoop, Hortonworks Hadoop.
Ofrece servicios profesionales y software para el ecosistema de Hadoop. Nació como
una empresa de la mano de Yahoo y Benchmark Capital en junio de 2011. Su
principal actividad es la de fomentar el uso de una distribución de Apache
Hadoop, Hortonworks Hadoop.
Es la empresa líder en tecnología Hadoop y la
que realiza mayores aportaciones a la comunidad como constructor de todo el ecosistema
Big Data. Ha lanzado recientemente su plataforma de datos Hortonworks que
incorpora el software puramente en Apache Hadoop de código libre. Posee fuertes
alianzas y compatibilidad para el Appliance de Teradata. Sus clientes Microsoft
y Yahoo resultan un buen escaparate para obtener mayor cuota de mercado.
Google que fue de los promotores de que Hadoop sea hoy un referente como
tecnología para explotar Big Data. Google a través de su servicio BigQuery ofrece servicios en la nube
basados en MapReduce ( es la base de Hadoop) con otra solución con base de datos
BigTable (solución OLAP que utiliza MPP) que pueden ser visualizados gracias a BigQuery
browser. Permite una solución escalable con precio por consumo (por hora y
espacio en disco) que intenta competir con Amazon. Ofrece servicios paralelos e
integrables para SQL con Google Cloud SQL.










{kind=link}
{kind=link}
{kind=link}